Published and edited by: Cheng Yu
WUST News - The ONTOWEB research team from the School of Computer Science and Technology at Wuhan University of Science and Technology (WUST) has achieved a significant milestone in AI-assisted interpretation of Chinese classics. The team developed a lightweight architecture with less than one-tenth the parameters of conventional large models. This architecture significantly surpasses existing large models in understanding classical Chinese texts. Targeting "efficient understanding of classical Chinese with small models", this achievement meets urgent demands in ancient text digitization, traditional culture preservation, and intelligent mobile applications. It forms a comprehensive methodological spanning three dimensions: semantic alignment, corpus construction, and cross-modal representation. Relevant papers have been accepted by ACM Transactions on Asian and Low-Resource Language Information Processing (ACM TALLIP, 2023), the SCI-indexed journal Information Processing & Management (2024), and the top AI conference ACL 2025.
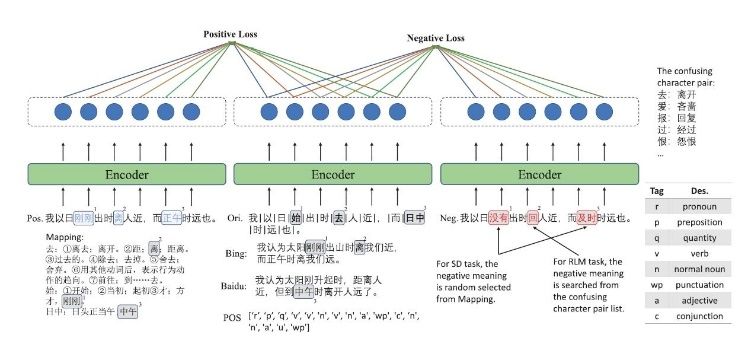
Figure 1: Pre-training Task for Synonym Discrimination Based on Contrastive Learning
To address the inherent diachronic semantic gap between classical texts and modern question-answering, the team proposed a contrastive learning-based pre-training task for synonym discrimination (Figure 1). This approach establishes precise mapping between Classical and Modern Chinese through character-level semantic distance measurement. Additionally, an enhanced dual matching network is designed to simulate the human reading process of "comparison before decision-making" using option-level attention reasoning chains. This method achieved an average absolute accuracy improvement of about 4% on public datasets such as Haihua, CLT, and ATRC, while limiting inference latency to within 1% of the original models.
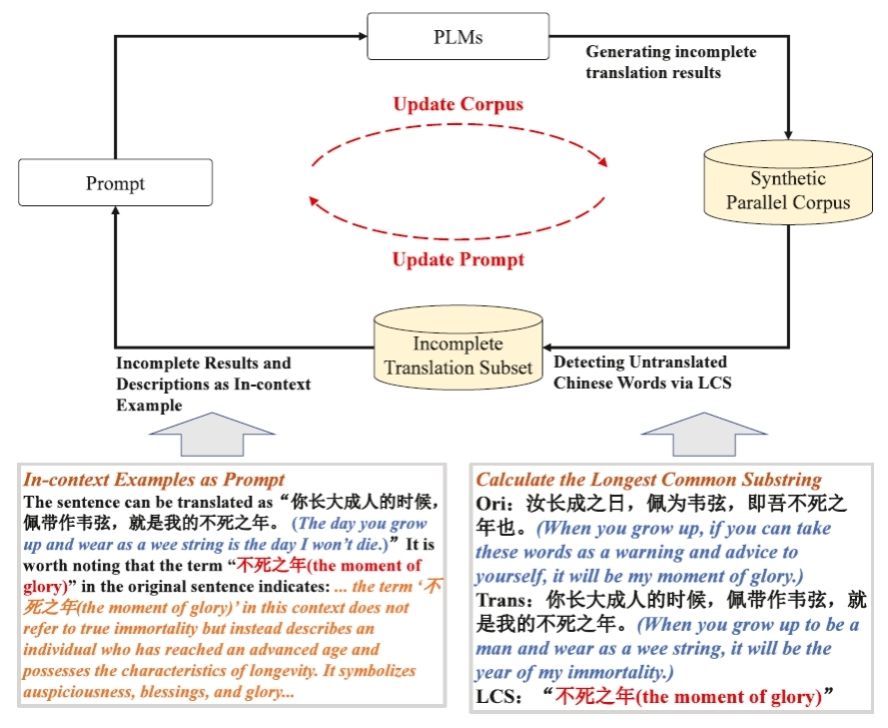
Figure 2: Progressive Translation Refinement Framework Driven by Large Language Models
To mitigate the training bottleneck caused by the scarce high-quality parallel corpora, the team designed a progressive translation refinement framework powered by large language models (Figure 2). This system automatically detects untranslated classical Chinese vocabulary using the longest common substring algorithm and iteratively refines through semantic description examples. The result is a highly aligned corpus of 37.2 GB, with the untranslated words ratio reduced to 5.8%. The construction cost is only 3% of traditional manual annotation, yet it is it provides sufficient data to fully train small models.
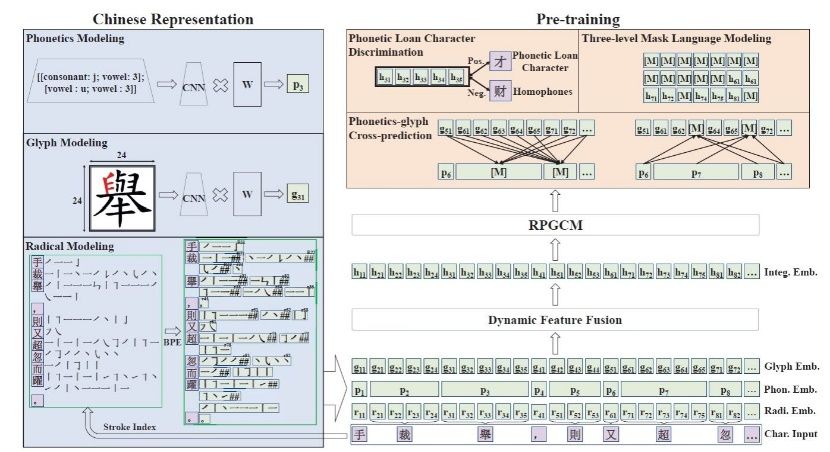
Figure 3: RPGCN Framework Diagram
At the level of form–sound–meaning synergy inherent in Chinese characters, the team incorporated radical-level phonetic and glyph representations into classical Chinese pre-training for the first time. A cross-modal fusion strategy was proposed, integrating stroke-based BPE subword segmentation, radical glyph ResNet encoding, and polyphonic pinyin CNN encoding. This was augmented by three pre-training tasks: variant character discrimination, three-level masked language modeling, and phonetic-form translation (RPGCN), significantly mitigating issues such as variant characters, ambiguities, and misreading of low-frequency characters. In evaluations on comprehensive understanding benchmarks such as C³Bench and WYWEB, this lightweight model consistently outperformed baseline systems by 3 to 7 percentage points, validating the effectiveness of joint modeling of form, sound, and meaning under small parameter conditions.
Additionally, the doctoral students involved in this project have completed the SDK packaging of the "Small Model Classical Text Engine", which operates successfully on mainstream mobile devices, providing offline support for real-time translation and interactive Q&A of classics like Records of the Grand Historian and Zizhi Tongjian. Compared to traditional BERT models, the accuracy of modern text translations and key Q&A after uploading a single page of ancient texts can reach 92%, with reducing training time by 80%. This work offers a low-cost, scalable intelligent reading solution for remote schools, grassroots museums, and public cultural service institutions.








